Your Filename Is Your Test Spec
Most codebases treat testing as a separate concern from code organization. Tests live in __tests__/ folders or have ad-hoc naming. You write a service that calls Stripe, and nobody notices it has no contract test until production breaks.
I fixed this with a naming convention.
The idea
Every .ts file's suffix declares what it is and what test it needs. You read the filename, you know the contract. No guessing, no lookup tables, no judgment calls.
create-checkout.api.ts → create-checkout.api.contract.test.ts
calculate-max-sends.unit.ts → calculate-max-sends.unit.test.ts
process-campaign.integration.ts → process-campaign.integration.test.ts
process-payment.orchestration.ts → process-payment.orchestration.test.ts
guarding-ai.ai.ts → guarding-ai.eval.ts
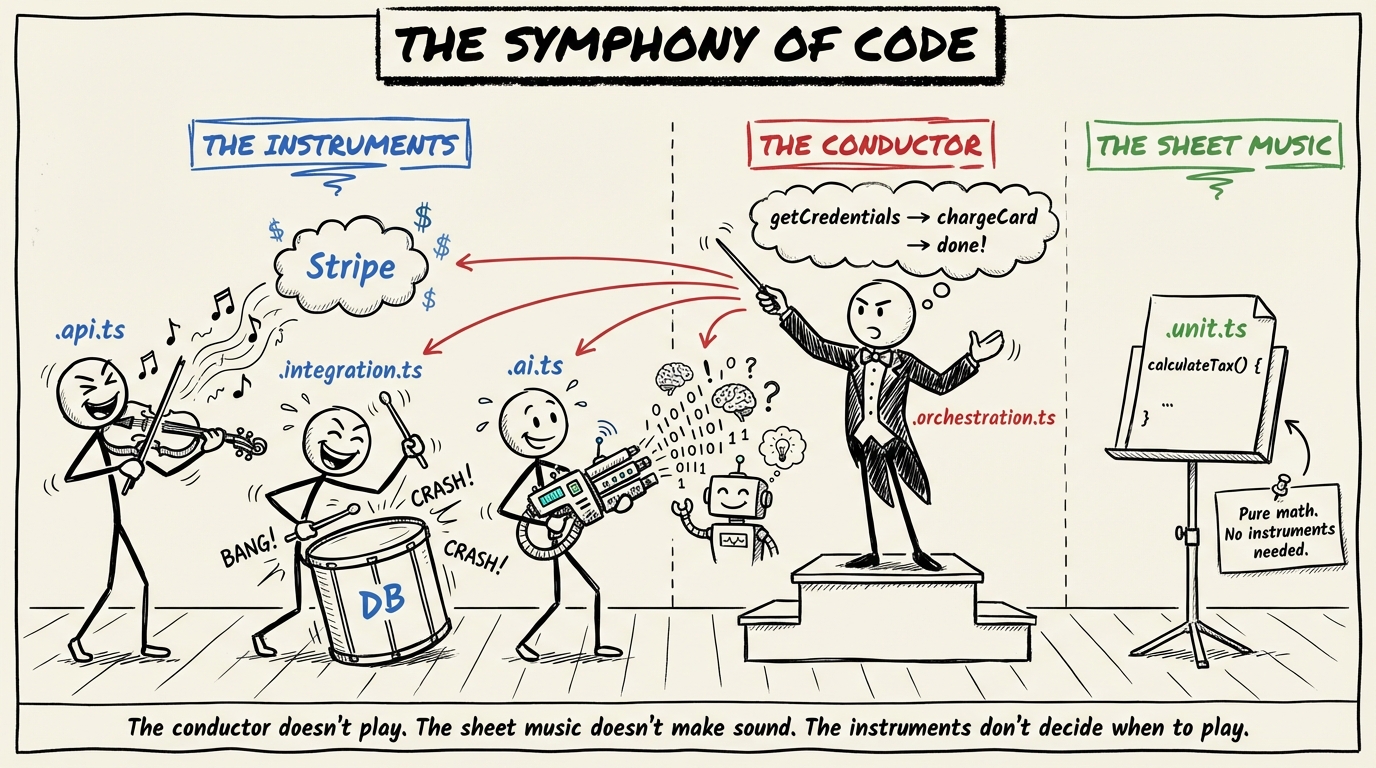
Think of it like a symphony:
.api.ts/.integration.ts/.ai.tsare the instruments. They interact with the physical world and execute I/O..unit.tsis the sheet music. It defines the pure rules, math, and logic, but makes no sound itself..orchestration.tsis the conductor. The conductor doesn't play an instrument and doesn't write the music — their only job is to read the sheet music, tell the instruments when to play, and pass information between them.
The full table:
| Suffix | Responsibility | Test type & mocking rule |
|---|---|---|
*.unit.ts | Pure logic: math, parsers, prompt builders, data mappers | Pure unit test: data in, data out. Zero mocks. |
*.orchestration.ts | The conductor: coordinates pure logic and I/O adapters. Contains control flow (if/try/catch). | Behavior unit test: verifies control flow. Heavy mocking of internal adapters. |
*.api.ts | External I/O: dumb client for 3rd-party HTTP APIs/SDKs | Contract test: real HTTP call, verifies response shape. |
*.integration.ts | Internal I/O: dumb client for DB, Redis, queues, file system | Integration test: uses real local/Docker infrastructure. |
*.ai.ts | AI I/O: dumb client for LLMs/AI models | Eval test: verifies prompt against real models. |
*.action.ts | Server action | Action integration test |
*.task.ts | Background task | Task integration test |
*.cron.ts | Scheduled job | Cron integration test |
route.ts | API route / webhook | Route integration test |
page.tsx | Next.js page | Playwright E2E |
Files that are self-documenting and need no test: *.schema.ts, *.types.ts, *.constants.ts, *.config.ts, *.data.ts, *.hook.ts.
How to classify a new file
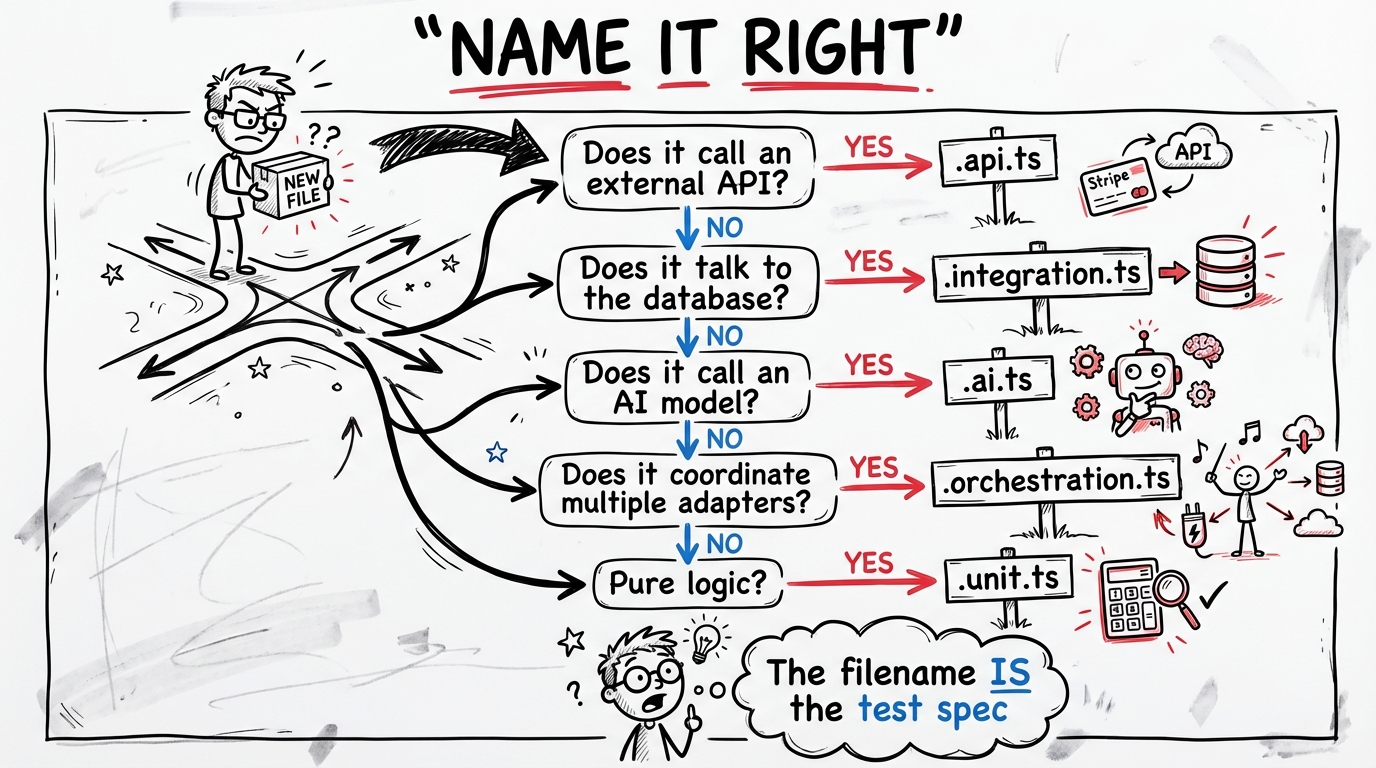
- Does it define types, schemas, constants, or atoms only? Use the matching suffix, no test needed.
- Does it call an AI model?
.ai.ts - Does it call an external HTTP API or SDK?
.api.ts - Does it read/write to a database, Redis, or trigger background tasks?
.integration.ts - Does it coordinate multiple adapters with control flow?
.orchestration.ts - Is it a server action, task, cron, route, or page? Already has its suffix.
- Everything else (pure functions, transformations, calculations)
.unit.ts
That's it. No ambiguity. Zero judgment calls.
Seeing it in action
The hardest naming problem I kept running into: "A function that reads from DB to get credentials, then calls an external API with those credentials." Where does it go? How do you test it?
With the convention, there's zero ambiguity:
getCredentials.integration.ts — The database instrument
export async function getCredentials(userId: string) {
return db.query('SELECT keys FROM users WHERE id = $1', [userId])
}
Test: spins up a test DB, inserts a mock user, verifies it fetches the key. Protects against schema changes.
chargeCard.api.ts — The HTTP instrument
export async function chargeCard(key: string, amount: number) {
return fetch('https://api.stripe.com/v1/charges', {
headers: { Authorization: key },
body: JSON.stringify({ amount }),
})
}
Test: actually hits Stripe's test network, ensures Stripe hasn't changed their payload shape. Protects against 3rd-party changes.
processPayment.orchestration.ts — The conductor
export async function processPayment(userId: string, amount: number) {
const creds = await getCredentials(userId)
return await chargeCard(creds.key, amount)
}
Test: mocks both getCredentials and chargeCard. Tests that the orchestrator passes the right variables between them and handles errors. Takes 2 milliseconds to run.
Why this works

Classification forces understanding
Before you write a file, you have to decide: does this touch a database? Call an external API? Use AI? Coordinate other files? Or is it pure logic? That decision shapes how you test it.
Most testing guidance is vibes. "Test what matters." "Use your judgment." "Aim for 80% coverage." Developers don't skip tests because they're lazy. They skip them because the system doesn't tell them what to write. This one does.
Coverage becomes trivial
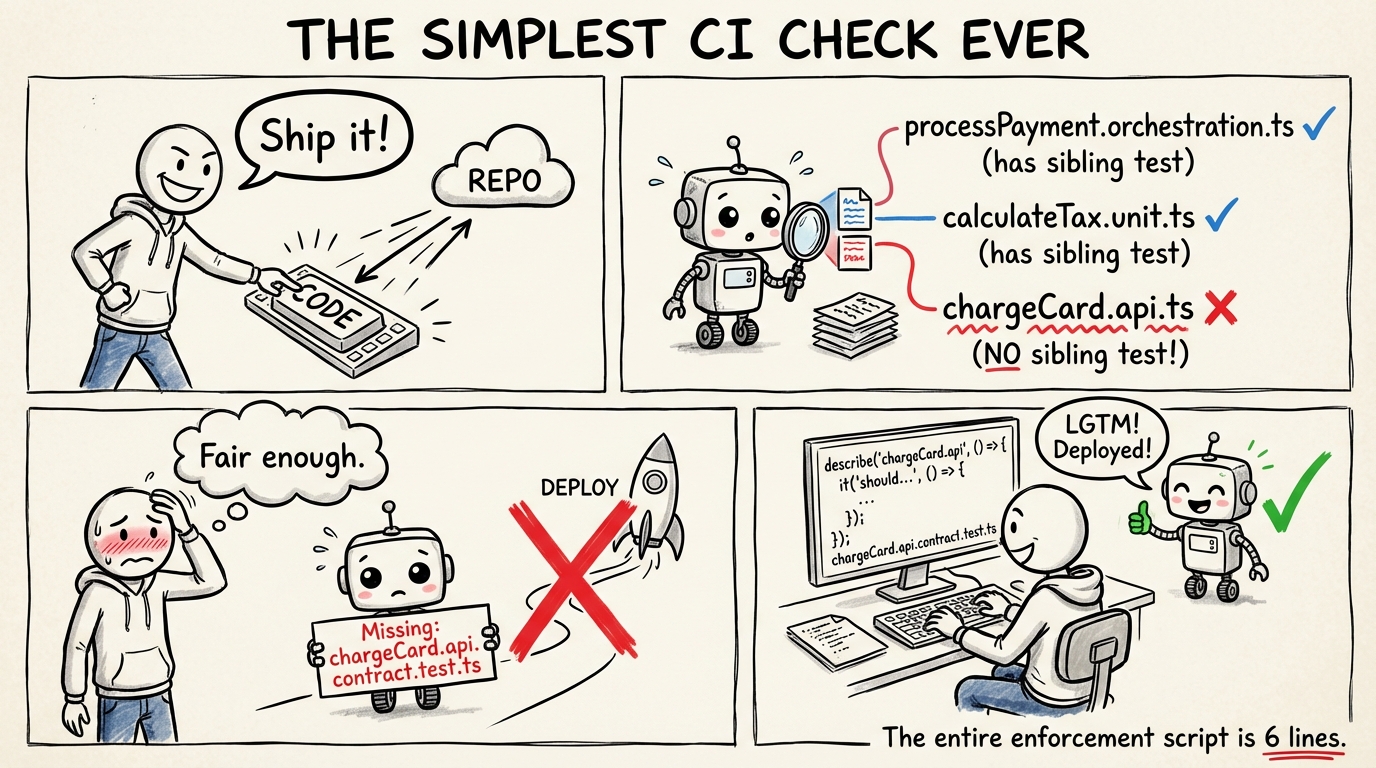
The entire enforcement script is essentially:
for (const file of sourceFiles) {
const expectedTest = getSiblingTestPath(file);
if (!existsSync(expectedTest)) {
errors.push(`Missing test: ${expectedTest}`);
}
}
No coverage tools. No config. No arguments about thresholds. If the sibling file exists, you're covered. If it doesn't, the check fails.
Filenames are externalized memory
I'm a solo developer. The thing I lose most is context from past-me. Six months from now I'll open a file I forgot about. The suffix tells me exactly what it touches and what test guards it. The filename is documentation that can't drift out of sync because it is the system.
Automate the architecture
Because the convention creates a perfect semantic split, you can enforce the entire architecture with two lint rules instead of tedious PR reviews:
Rule 1: Files ending in .unit.test.ts are forbidden from importing jest.mock, vi.fn, or any mocking library.
Rule 2: Files ending in .unit.ts are forbidden from importing files ending in .api.ts, .integration.ts, or .ai.ts.
The file suffix dictates the architectural boundary. Pure logic stays pure. I/O adapters stay dumb. Orchestrators coordinate. The linter enforces it all at build time.
How mature codebases actually do this
They don't.
- Rails / Django / Go test files mirror the source tree.
billing.rbgetsbilling_test.rb. The test type is implicit from the folder. - Java / Spring uses annotations (
@SpringBootTestvs@Test) to distinguish test types. The filename says nothing. - Google's monorepo is the closest prior art. Every directory has a
BUILDfile that tags each test assmall,medium, orlarge— controlling timeout, resource access, and when it runs. Small tests can't touch the network. Large tests run nightly. Google does classify tests by type — but the classification lives in a separate build file, enforced by Bazel. You need Google's infrastructure to make it work. - Most JS/TS codebases use
.test.tsfor everything. Maybe a separate Jest config to split unit from integration.
My convention is Google's idea made zero-config. The same semantic classification — what kind of I/O does this touch, what kind of test does it need — encoded directly in the filename. No build system. No config files. No infrastructure. You read the suffix, you know the contract.
The industry standard is: name everything .test.ts and figure out what kind of test it is by reading it. There's no enforcement that a file calling Stripe has a contract test instead of a unit test with mocks. You find out the test was wrong when production breaks.
My system makes that failure mode impossible. The suffix is the specification. Wrong suffix means wrong sibling test, and the script catches it before anything ships.
The unbreakable repo
Here's where this gets interesting at scale.
The Ralph Loop — AI writes code, you verify through types, lint, and tests — is how most AI-native developers ship now. The bottleneck was always verification. You can generate code fast, but how do you know the AI wrote the right kind of test?
With the filename convention, the Ralph Loop closes completely:
- AI creates a new file. The suffix forces it to classify what the file does.
- The sibling test check demands a test file exists with the correct suffix.
- The lint rules forbid
.unit.tsfiles from importing I/O adapters, and forbid.unit.test.tsfiles from using mocks. - Types catch the rest.
The AI can't cheat. It can't write a unit test with mocks for something that calls Stripe. It can't skip the test. It can't put database calls in a .unit.ts file. Every violation gets caught at build time, automatically, before anything ships.
Run this on a repo of any size — 50 files or 5,000 — and the guarantees hold. The convention scales linearly because the enforcement is per-file. No global analysis, no coverage thresholds to argue about, no "we'll add tests later." Every file declares its contract. Every contract is enforced.
The best part: you can retrofit this onto any existing repo. Drop the convention into your CLAUDE.md, fire up Claude Code on a Max subscription while the unlimited usage is still priced where it is, and let it Ralph Loop through the whole codebase. The AI does the mechanical work — renaming billing.ts to billing.api.ts, creating billing.api.contract.test.ts — while you review the classification decisions. A repo with zero test discipline becomes a fully enforced codebase in an afternoon. It'll cost you a day of attention and a subscription you probably already have.
That's what makes the repo unbreakable. Not the tests themselves — the fact that the system makes it structurally impossible to skip them.
The operating principle
What you haven't tested, you haven't built.
The file suffix convention is just the enforcement mechanism. The actual idea is simpler: move the "what kind of test does this need?" decision from an afterthought into the moment you create the file. Make it impossible to skip. Make it impossible to get wrong.
If you name the file, you've already written the test spec.